Big Data: Analysis made simple
What is Big Data?
We often hear about Big Data and wonder what it means, what are the implications, and how we can get value from it, and here we’ll provide some examples.
First of all, we need to define what is Big Data, and considering the broadness of the term, we will limit ourselves to the amount of records, and consider Big Data hundreds of millions to billions or more.
It’s quite common to find companies that have a lot of data but don’t know how to get value from it or if it has value to begin with.
Useful Big Data
Big Data can be extremely useful and valuable, but you have to know where to look.
Social media networks such as Twitter, Facebook, YouTube and so on, generate huge amounts of data every second, and this type of data is one of the most valuable types of data because it provides a way to know how people think, what they want, what drives them, what are the current trends and so on.
One of the most valuable sources of social media data at the moment is Instagram. It’s one of the most important social networks, with a user base in the billions and an essential platform for many types of companies to capitalize on.
Step 1 - The data
To begin with, we need to see what the data looks like, and for Instagram, with just a quick look, we can see that we have user profiles, which contain the amount of followers, their biography, etc. and posts, which have amount of likes, comments, hashtags, mentions and other useful information.
For now, let’s focus on those first things that we see when looking into an instagram profile, the amount of followers, the amount of likes in the posts and the hashtags and mentions.
What interesting things can we learn from this data?
Let’s start by the simplest thing we can come up with, and count the amount of times a hashtag was used, along with the amount of likes and followers it has.
Step 2 - Data processing
Now that we know what we want and what our data looks like, we can begin by setting up a program to go through the data and extract the information we want.
First, we need to go through all the profiles and extract all the hashtags they used, this way we can tackle our first goal of knowing how many times a profile used a hashtag.
For that, we set up a single regular expression to extract from text all the hashtags.
import (
"regexp"
)
// Our hashtags regex
var hashtagsRegex *regexp.Regexp
func init() {
// Compile the regex
hashtagsRegex, _ = regexp.Compile("(?:#)([\\p{L}\\d_](?:(?:[\\p{L}\\d_]|(?:\\.(\\?!\\.))){0,28}(?:[\\p{L}\\d_]))?)")
}
That regex looks fairly complicated, but all we need to know is that it will match Instagram’s hashtag format, without giving us false positives, for example #...hello... is not a valid hashtag, but #hello is.
Now that we have the hashtags regex, we need to run it through all the user’s posts and find all the hashtags, then assign them only once per profile.
This is quite simple, we set up a function to extract the hashtags for convenience
// GetHashtags returns a slice with all the hashtags
func GetHashtags(t string) []string {
return hashtagsRegex.FindAllString(t, -1)
}
Now that we have the hashtags, we can proceed to do the same thing with mentions, which is fairly similar, just changing the # symbol with an @ in the regex is a good starting point.
Finally, we need to iterate through all the profiles and count the amount of times each hashtag was mentioned. Then save the data to a file.
func saveMostUsedHashtags() {
// Initialize a slice for storing the hashtags with the amount for each
hashtagAmounts := make(map[string]int)
// profiles are all the profiles with their hashtags
// for each profile in the profiles
for _, p := range profiles {
// For each hashtag in the profile
for _, h := range p.Hashtags {
// Increase the amount of times the hashtag was found
hashtagAmounts[h]++
}
}
// Create a file for storing our hashtags
f, err := os.Create("hashtags_export.csv")
// Stop the program if we can't create the file
LogPanic(err, "ERR CREATING FILE")
// Get a list of hashtags ranked by incidence
matches := RankByAmount(hashtagAmounts)
// Save up to 2k in a csv-like format
for _, v := range matches.MostCommon(2000) {
_, err = fmt.Fprintf(f, "%s,%d \n", v.Key, v.Value)
}
// Close the file
err = f.Close()
// Stop the program if we can't close it
LogPanic(err, "ERROR CLOSING FILE")
}
We repeat the same process with the mentions and create a second file called mentions_export.csv
After complete these operations, we will get a file with all the hashtags, another one with all the mentions and the amount of times each of them was used.
Step 3 - Loading the data
The analysis and displaying of the data should be fairly simple now.
With start with a new jupyter notebook and we add the exported files to our directory, to load them for displaying.
# Our import statemnts, everything we need
import matplotlib.patches as mp
import pandas as pd
import matplotlib.pyplot as plt
# The amount of hashtags we want to read from the files
READ_AMNT = 200
# Loading our data
df = pd.read_csv(
"./used_hashtags.csv",
names=["hashtag", "used"],
usecols=["hashtag","used"],
index_col=False,
skiprows=1,
nrows=READ_AMNT)
df1 = pd.read_csv(
"./liked_hashtags.csv",
names=["hashtag","liked"],
skiprows=0,
index_col=False,
nrows=READ_AMNT)
df2 = pd.read_csv(
"./followed_hashtags.csv",
names=["hashtag","followed"],
skiprows=0,
index_col=False,
nrows=READ_AMNT)
# Merging the data into a single Data Frame for displaying.
# Note that we are merging the first and second data frames
# and then merging them into the third one. This way we get
# the biggest number, which in this case is the 'followed'
# amount to be our column for sorting as descending
df = pd.merge(df1, df, on="hashtag")
df = pd.merge(df2, df, on="hashtag")
df = df.nlargest(20, "followed")
We add all that code into the first cell of our notebook and we run it. Now we have loaded our data in a pandas Data Frame called df, which is the convention.
Step 4 - Displaying the analysis results
# Set up a figure of the size we want, the canvas size of our chart.
fig = plt.figure(figsize=(15, 8))
# Set the background color
fig.patch.set_facecolor('white')
# Display the hashtags vertically instead of horizontally
plt.xticks(rotation='vertical')
# Set the size of the font
plt.tick_params(labelsize=18)
# Set the background color of the axis, otherwise it would be transparent
plt.rcParams['axes.facecolor'] = 'white'
# Set our colors
YELLOW_C = "#F5B12E"
RED_C = "#ED4F33"
BLUE_C = "#2E2963"
# Plot the amount of times the hashtag was used in a dark blue color
plt.plot(df["hashtag"], df["used"], color=BLUE_C)
# Plot the amount of times a hashtag is followed in a red bar
# this will be the tallest bar
plt.bar(df["hashtag"], df["followed"], color=RED_C)
# Plot the amount of times a hashtag is liked, with bars on top
# of the red bars, we can do this because the numbers are smaller
plt.bar(df["hashtag"], df["liked"], color=YELLOW_C)
# We set a logarithmic scale to be able to make a useful interpretation
# of the data, because the numbers are so far apart from each other
plt.yscale('log')
# We set the labels
red = mp.Patch(color=RED_C, label='Followed')
orange = mp.Patch(color=YELLOW_C, label='Liked')
blue = mp.Patch(color=BLUE_C, label="Used")
# We add the title
plt.title("Logarithmic scale")
# We add the legend
plt.legend(handles=[red, orange, blue])
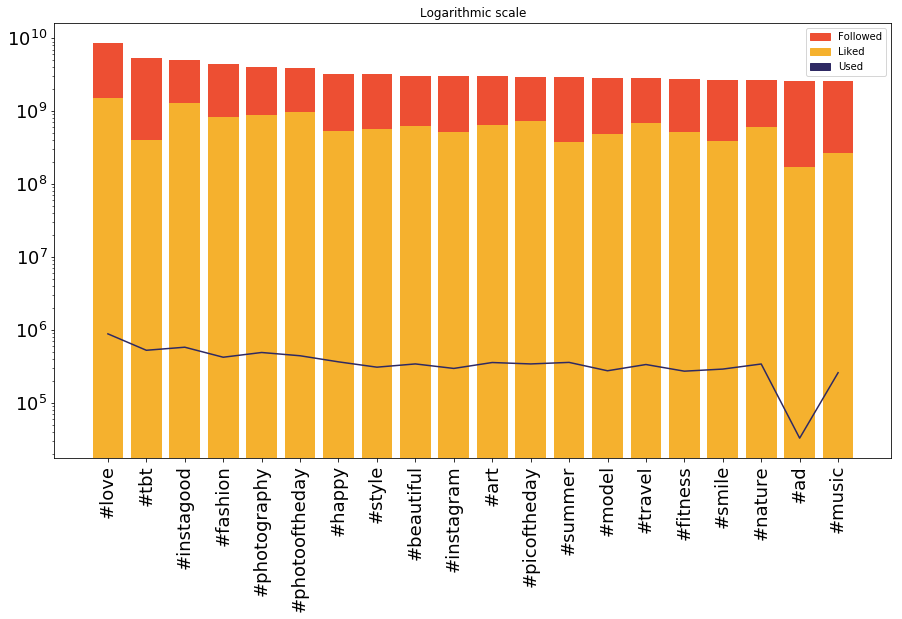
After we run the code above, we get this graph
Which shows the 20 most used, liked and followed instagram hashtags in the world
DISCLAIMER: Our client does not store any data from Instagram.